Evaluation Structure
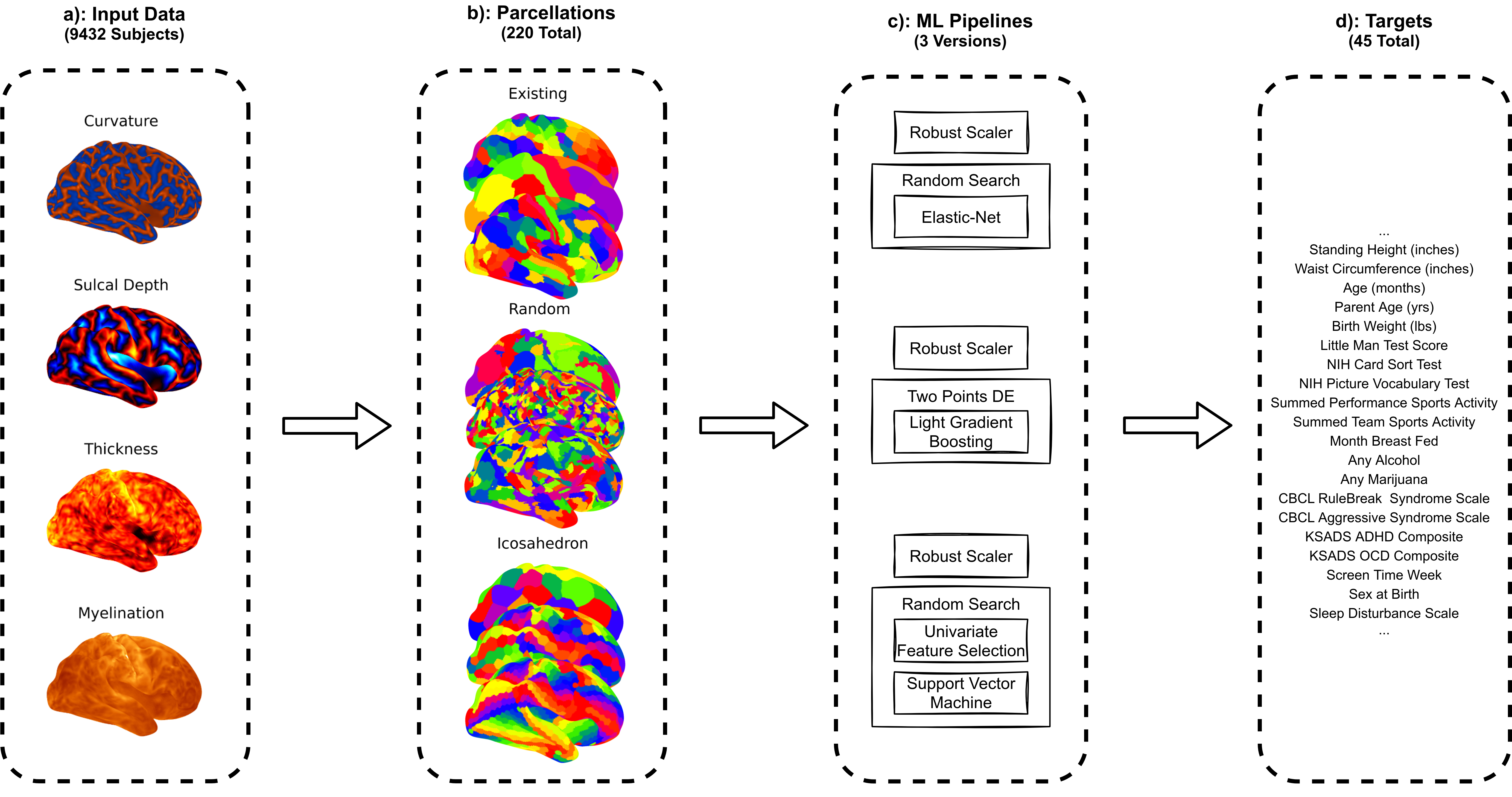
To evaluate a given target variable, parcellation, or machine learning strategy’s performance, we defined an explicit framework to compare different combinations of methods. We evaluated each combination of target variable, parcellation and ML pipeline with five-fold cross validation using the full set of available participants. This evaluation strategy is well known as K-Fold cross validation.
-
Each of the validation folds, including any nested parameter tuning folds, were conducted such that participants from the same family were preserved within the same training or testing fold. This consideration was made as the ABCD Study was specifically designed to recruit a large number of siblings and twins.
-
The 5-fold structure was kept constant and therefore comparable across all combinations of ML pipeline, target variable, and parcellation (including both the base experiment and multiple parcellation experiment). In the case of missing target variables (see NaN Counts in Target Stats), those participants with missing data were simply excluded from their respective training or validation fold (i.e., if missing from a training fold then just not included in training, if missing from a validation fold then not included in generating the validation metric).
-
In principle while it may have been more reliable to perform multiple repeats of the five-fold evaluation, the additional computation would have proved intractable given the already considerable runtime required for even a single 5-fold evaluation.